Can someone help explain all cases, where 1. A>B, 2. A<B, 3. A=B.
Greg discussed it briefly in the solution video for 1. A=B, and 2. A not equal to B, but I didn’t understand either case.
TIA!
Can someone help explain all cases, where 1. A>B, 2. A<B, 3. A=B.
Greg discussed it briefly in the solution video for 1. A=B, and 2. A not equal to B, but I didn’t understand either case.
TIA!
Can you try making the examples yourself?
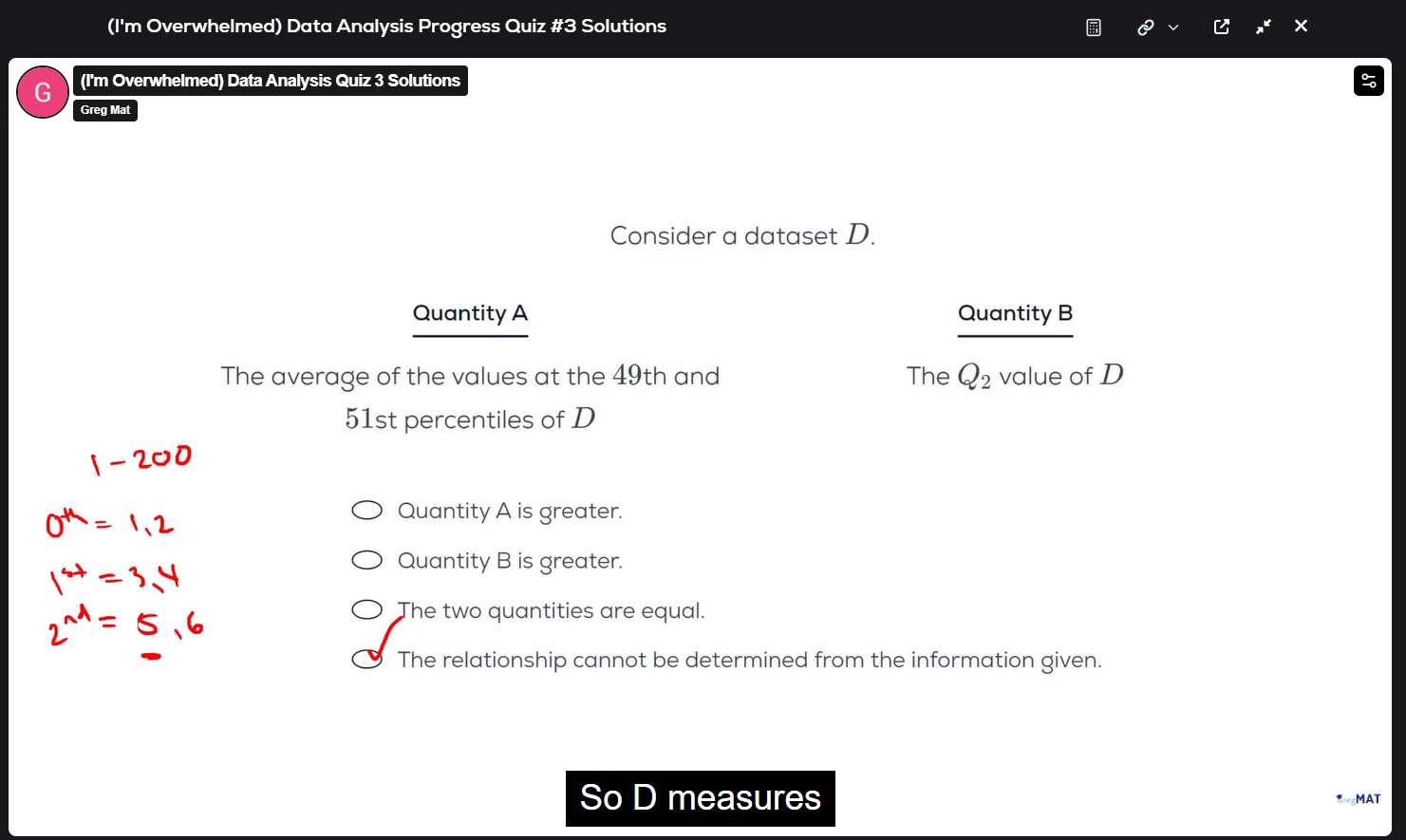
Yes. I tried for the following cases:
n=200
Q2=100.5
Average of 49th and 51st %iles=101.5
n=100
Q2=50.5
Average of 49th and 51st %iles=51
In both cases A>B.
Also for counting which numbers fall in which %ile - I understand that by definition, nth%ile means number of observations that are greater/better than n.
Thus we start from 0th %ile because those are the number of observations that are greater than 0% of the people, and we end at the 99th%ile. So the %ile counting goes from 0th %ile to 99th %ile.
I want to clarify that we start counting from the 0th place only for %iles, not deciles, quintiles, quartiles? And if that’s the case, why is that we only do this for %iles?
Does “n = 200” mean a list of counting numbers from 1 to n? What about a dataset with repeats?
number of observations above approximately (depends on whether we follow the inclusive/exclusive definition of a percentile) n\% of all elements in a dataset.
You can have a 0th quartiles, deciles, quintiles, and the like. You usually don’t care about them because they aren’t the “markers” responsible for partitioning a finite set into roughly equal sizes; rather, they function more like “boundary markers”.
Thanks for the clarification on %iles and boundary markers, it helps!
Yes, I took n=100 and n=200 for the list of counting numbers from 1 to n
I also tried with repeats, where n=200 and each counting number is counted twice (1,1,2,2,…99,99,100,100).
This again gives me:
Q2=50.5
Average of 49th and 51st %iles=51
We can only approximate what data lies in the 49th or 51st percentile, so i’m not sure how you “accurately” determined the corresponding values. Your definition need not be the standard GRE follows, which is why i mentioned “approximately” in the previous comment.
Anyhow, by repeats, I meant a dataset consisting of only 1 element repeated like 100 times or 200 times. Without computation, you should be able to figure out the relationship between Quantity A and Quantity B.
Case 1:
Okay, I see that if we take the same number repeated 200 times, we have A=B.
Case 2:
However, if we cannot accurately determine the 49th or 51st percentile, would that mean we don’t do any calculations to approximate it? Is that why we concluded D is the answer?
Not really. No matter which (reasonable) definition you pick, it will be possible to get A>B with that definition, and also possible to get B>A with the same definition. I would not pick D solely because you don’t know which definition the GRE references.
Alternatively, you could construct a case 2 like so:
Suppose you have a dataset with 1000 observations, where you have the value “0” 495 times, the value “1” 10 times, and the value “10” 495 times.
Then there’s really no reasonable way to define percentiles that wouldn’t result in A=5 and B=1
.
I’m don’t think I get it yet. I’ll revisit the topic later and come back with any questions. Thanks!
Do you get the 1000 observation example? No matter what (reasonable) definition you use to retrieve the element in the 49th percentile, its position will be restricted around 490, 491, or perhaps even 492 . However, since our dataset contains 495 copies of zeroes occupying the first 495 positions, we’re guaranteed that the 49th percentile element will be 0 regardless of the definition used.
Similarly, the 51st percentile element must be 10 because the elements in position 510, 511, and 512 are all “10”. Hence, there’s no ambiguity on what the element in the 51st percentile element will be because the entire neighborhood of possible elements that could fall at the 51st percentile (depending on the definition used) contain the value 10.
The median we know how to compute:
For datasets with an odd number of elements, the median lies roughly half-way through the ordered dataset. In particular, if you can remove an element and in turn split the datasets into two equal halves, then that must be the median. More precisely, the median is the element at position \lceil{n/2} \rceil, where n corresponds to the number of elements in our dataset, and \lceil \cdot \rceil denotes the ceiling function , i.e., the smallest integer greater than or equal to the quantity inside.
For datasets with an even number of elements, the median is defined as the average of the largest element in the lower half and the smallest element in the upper half, once the dataset is sorted and evenly split. For example, to find the median of [1,2,3,4], we’d first split it two equal halves: [1,2] and [3,4]. We then average the maximum of the “lower half (list with smaller numbers) and the minimum of the upper half (list with the bigger numbers) to get \operatorname{average} (2,3) = 2.5 Formulaically, it is simply \operatorname{average} ( n/2, \lceil (n + 1)/2 \rceil), where the variables represent the same thing they did above.
Accordingly, a 1000 element datatset can be split into two 500-element datasets. Thus, the median is the average of the 500th and the 501st element, which is just 1 in this case.
Hey cylverixxx, I just revisited the topic and went through this explanation.
It is really helpful and yeah I do see how the 2 can be wildly different.
Although conceptually I don’t think I have understood it well enough, but the example you provided by choosing numbers really helps. Thanks!